Introduction
As a first-year international student at Tokyo Tech, my pursuit of an internship led me to discover Nefrock, through a list of companies contracted with Tokyo Tech. Nefrock was 5 minutes away so I figured I would go with my CV in person. That must have left an impression, because after a couple interviews I was accepted for an internship.
At Nefrock, I was assigned to work on the EdgeOCR project. EdgeOCR is a library that facilitates reading text with Latin and Japanese letters from a camera feed in real time (Optical Character Recognition), and is mainly designed to be run on mobile devices (on the “Edge”). To achieve this, it uses two separate types of AI (neural networks): The first determines where on the current frame text is visible (detection), while the second AI then reads the text at those locations (recognition). Using the EdgeOCR SDK, users can easily build applications to read, for example, expiration dates on food packaging.
An important part of EdgeOCR is its real time performance. My task at Nefrock was to create a benchmark suite for the library to continuously monitor the performance during its future development. Using benchmarks, bottlenecks in performance can be determined, and possible performance degradation due to new code updates can be detected.
Benchmarking
Micro benchmarks are the easiest kind of benchmark to code, and as such were a good opportunity to study the structure of the EdgeOCR library. Micro benchmarks measure the runtime duration of individual functions in isolation. This kind of benchmarking is fairly common, and mature open-source libraries exist to make this task easier. I picked google-benchmark, which I first had to learn how to use, but it quickly allowed me to write benchmarks of functions from image pre-processing to the post-processing of neural network output.
With the most important functions measured, and a better understanding of how the library works, the next goal was to simulate the actual use case of the library: Running the full text recognition pipeline on a continuous stream of images. For this, I came up with a simulation that feeds images to the library at a fixed frame rate of about 30fps. I achieved this by skipping frames if processing of the previous frame was not yet finished. This mimics the behavior of a phone camera.
One restriction was that I was asked to make as few modifications to the library as possible.
Due to this restriction, I chose Perf to profile the execution of this simulation. Perf is a Linux command that uses so-called performance counters to sample processes. It will sample the program thousands of times per second, and allows us to track which library function was executed at any given time during the execution, including its call stack.
By default, it will output a list that will look something like the following:
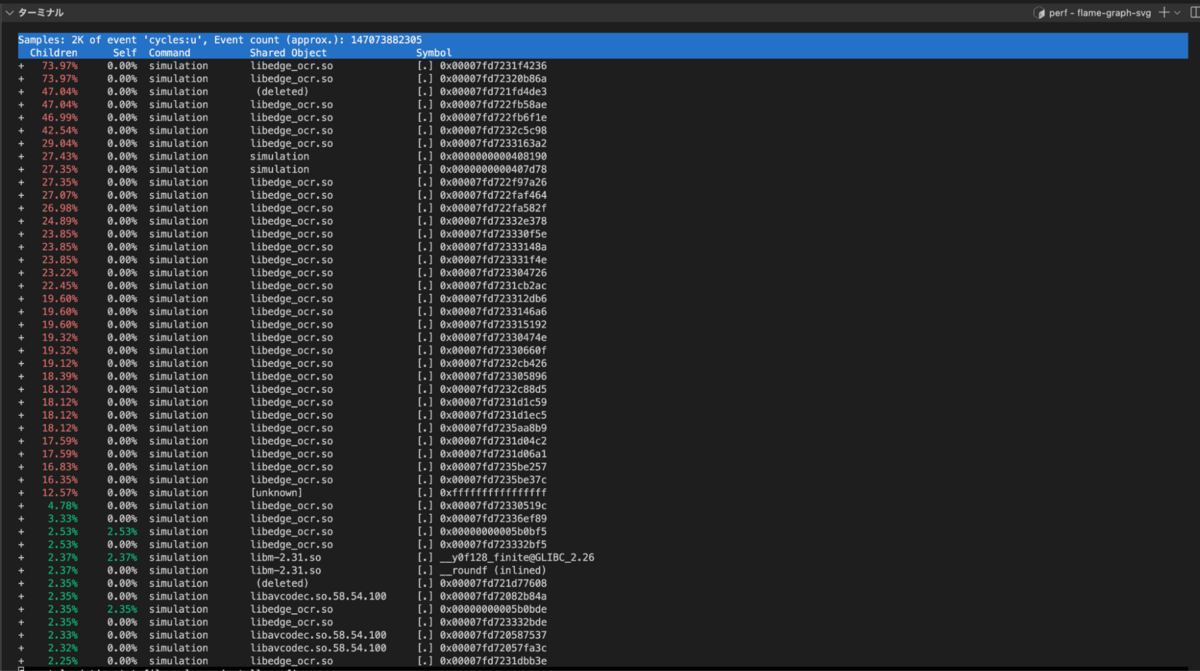
This one dimensional list is hard to interpret, and thus not very useful. Flame Graphs are a common visualization tool for this kind of data. They better represent the hierarchical nature of the call stacks, and allow detection of bottlenecks at a glance.

Using the default options when running perf, I found that in both the list and the flame graph many functions were only represented by a number (a pointer), and not by their actual name. This means that debug symbols were not properly associated with the functions. The problem resides in the fact that the stack that stores the call graph information was not large enough. Indeed, by increasing or decreasing this stack we can observe the share of the unknown fluctuate. Setting a proper size with a command line argument largely fixed this problem.
Aside from this issue, we can see that most of the time is spent inside the forward (neural network invocation) functions, which is to be expected. The careful reader may notice that the stack containing the text recognition invocation is listed separately from the “main” function. Recognition work is actually done asynchronously on separate threads, and in perf this leads to them not showing up as part of the “main” function invocation. Recognition is run asynchronously to allow for more frequent execution of the detection network, which in turn allows for smoother tracking of detected text across frames. Certain optimizations in EdgeOCR depend on this tracking.
Profiling on Android
The actual target devices for the EdgeOCR library are Android phones. However, so far all benchmarks were only run on a regular computer. The reason is that Android phones generally use Arm processors, requiring cross-compilation, and are also generally harder to use during development due to restrictive permissions (for example, execution permissions are only available in select folders like `/data/local/tmp`).
The cross-compilation problem was luckily rather easy to solve since a setup for cross-compilation of the library for Android phones was already in place. Adding the simulation compilation to this setup took little effort. However, when executing the simulation, the frames would refuse to load. It turns out that OpenCV cannot load video files on Android, and I had to resort to extracting the individual frames to image files, and loading them separately.
Another problem is that `perf` itself is not available on Android. Luckily there is a near drop-in replacement called `simpleperf`, which was another reason I chose `perf` in the first place. When processing the profiling data gathered on the phone, I discovered that debug symbols were not available and the flame graph would contain only “unknown” functions. There are scripts which allow gathering of the necessary debug symbol data in a form that the flame graph creation scripts can read. While this did work quite well, I sadly did not have time to write scripts to automate this process before the internship period ended.
The Remaining Tasks
Aside from completing the scripts to automate the creation of the flame graph from the execution on the phone, making this benchmarking process a part of the CI/CD pipeline of the EdgeOCR library is a significant task. Ideally, the benchmarks could be run on a set of Android phones automatically whenever changes are made, and a warning could be given if performance degrades due to these changes.
Thanks
I would like to thank Peter for recommending me for this internship even though I was not fluent in Japanese and for helping me throughout the internship. I would also like to thank Nefrock CEO Toshiyuki and his team for recruiting me, for their warm welcome, and for allowing me to have a flexible schedule.
Thank you for this month spent together.